
By Anne Chemali
July 28, 2025
The ATA Language Technology Division (LTD) held its quarterly ATA TEKTalk on July 10, 2025, featuring Ondřej Matuška, a linguist and the head of sales at SketchEngine, a corpus system developed by Lexical Computing, a company based in Brno, in Czech Republic. His role includes promoting the use of corpora among linguists and language professionals and running training events and workshops. Ondřej also contributes to developing the user interface and improving the user experience of SketchEngine.
SketchEngine is a comprehensive language analysis system used by various language professionals including linguists, teachers, translators, interpreters, and lexicographers. While the system contains many tools primarily designed for academic language research, one particular feature – terminology extraction – is especially valuable for translators and interpreters.
The developers created a separate, simplified web interface called OneClick Terms. It is designed to be streamlined and user-friendly, with a simple “START HERE” button.
What it term extraction and how is it done?
Term extraction refers to identifying words or phrases that have a specific meaning in a given context, or in a specific document. Linguists use term extraction to build a list of phrases which need to be translated with special care or need to be considered with special attention, because they carry an important meaning in the document. It is the preliminary work before building a glossary for your translation or for your interpreting assignment, which you can then use in association with a CAT tool or any other equivalent tool.
The best terminology extraction tool will always be the human brain, Ondřej said. The quality of human extraction is in fact very high, but unfortunately, the speed is also very slow. If you’ve got a document of two pages, the best way to extract terminology is just to read it and underline the terms. But if you’ve got 100,000 pages, it’s impossible to do so. So, how do we imitate the human brain?
What the human brain does to identify terminology is to somehow take what it reads and compare it to its linguistic experience, to what it knows, or to what it has in its memory about the language. OneClick Terms was designed to emulate the human brain’s tasks.
OneClick Terms interface Demo
The interface is designed to be user friendly and is so intuitive that the learning curve is extremely flat. Note that 36 languages are currently supported. Languages appearing in the language list with a yellow star offer a higher level of support. To start a term extraction, the user selects two languages and then clicks on the “START HERE” button.
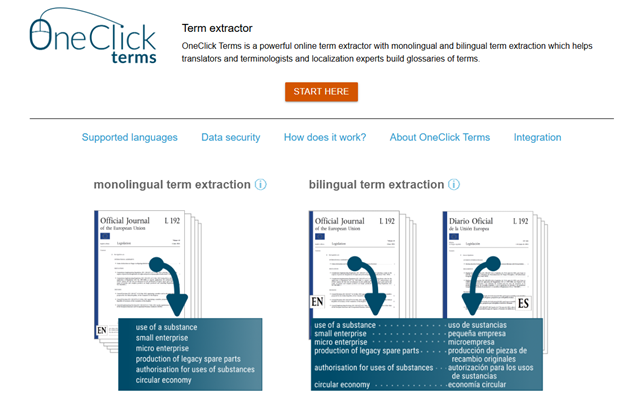
The terminology extraction tool offers three ways to extract terms: from monolingual texts, from bilingual aligned texts (like translation memories in TMX or XLIFF format), or from unaligned bilingual texts that are translations of each other, which the system will automatically align.
Monolingual extraction process: The demonstration used an English PDF from the Official Journal of the European Union. The tool extracts text, assigns parts of speech, analyzes morphology (gender, case, etc.), and categorizes results into single words (useful for acronyms and product names) and multi-word phrases. Terms are presented in their basic forms (singular, first case) regardless of how they appear in the document.
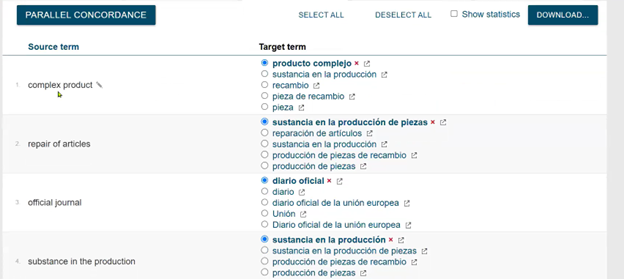
Bilingual extraction process: Using English and Spanish versions of the same EU document, the tool converts text to plain text, assigns grammatical properties, considers language-specific rules (like gender agreement between adjectives and nouns), aligns terms between documents, and presents multiple translation candidates with the ability to view source sentences for verification.
The performance advantage:
The goal of OneClick Terms is to find the right balance between extracting terms that are not really terms and missing an important term in the document.
Here’s a summary of the top features mentioned for increasing linguist productivity:
1. OneClick Terms considers the grammar and linguistics rules of each language, not just statistics.
2. Cleaner output with less noise: OneClick Terms produces much cleaner results compared to other terminology extraction tools, meaning there are fewer irrelevant or incorrect terms in the output.
3. Faster review process: Because the output contains less noise and irrelevant information, linguists can work through the extracted terms more quickly and efficiently.
4. Standardized term presentation: Terms are automatically presented in their basic grammatical forms (singular, base case) rather than in the various declined, plural, or case-specific forms they might appear in within the source text. It handles morphological variations across different languages.
5. The ultimate word selection belongs to the users: They can accept one of the recommended terms, enter a new term of choice, or they can eliminate some terms from the termbase export altogether.
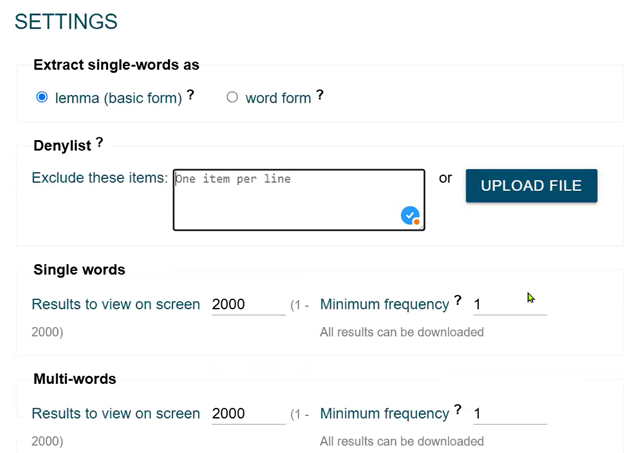
User settings
OneClick Terms offers several customization settings to refine terminology extraction results:
Deny list feature: Users can exclude specific words from results by copying/pasting terms or uploading a file containing words to be filtered out.
Character requirements, including:
- Default setting requires terms to contain at least one letter (excludes pure numbers)
- Option to allow “only letters and numbers” (removes hyphens, dashes, slashes)
- Option to include only lowercase terms to avoid proper nouns (not recommended for all languages)
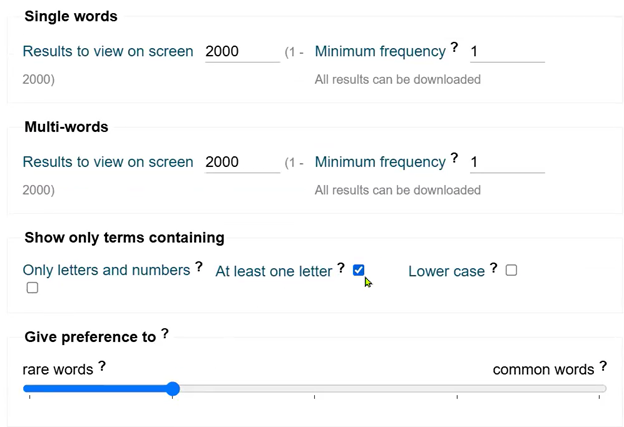
Specificity slider: A slider allows users to adjust the balance between rare and common words:
- Sliding toward “Rare words” prioritizes highly specific terminology
- Sliding toward “Common words” includes less specific terms that might still be considered terminology
- Example given: “average value” – could be terminology but is also used in general language
How does terminology extraction work in conjunction with
CAT tools?
The tool essentially streamlines the process of detecting and cataloging client-specific terminology for use in translation projects.
When translators receive assignments from new customers, they may not be
familiar with the client’s specific terminology, even if they know the general
field. Companies often have their own unique terminology conventions.
OneClick Terms serves as an efficient method for building these terminology databases. Once the user is done reviewing the extracted term candidates, the entire list can be exported in multiple formats (Excel, text, TBX), then imported in a CAT tool. CAT tools can check terminology usage, but they require a reliable pre-populated termbase to function effectively.
Background mechanics behind OneClick Terms
Traditional term extraction tools use n-gram frequency analysis, where n-grams are sequences of words (e.g., “I love you” is a 3-gram, “I love” is a bi-gram). These tools identify word sequences that appear frequently in documents, assuming high frequency indicates terminology. They may include stop lists to exclude common words like conjunctions or articles.
But the standard definition of a term as “a word or phrase with specific meaning within a particular domain” is difficult to program into computer systems because determining “specific meaning” is complex for automated processes.
Terminology extraction is actually highly subjective, not objective. Here are examples:
- “Return on investment
analysis model” – should this be one term or split into “return
on investment” and “analysis model”? - How about “Median
value sample size”? – what qualifies as a true term versus general
language?
Practically, rather than asking “Is it a term?” the better question is “Is it useful to include it in my terminology database?” This focuses on practical utility for consistent translation rather than academic classification. Even non-technical phrases might be worth including if they need consistent translation across a project.
The frequency marker:
Instead of traditional definitions, a term is redefined as something that appears more frequently in the domain-specific document than in general language – a concept that can be programmed into computers.
OneClick Terms compares the words it finds in the uploaded documents to a massive general language corpus (60 billion words in English) that covers all topics and represents language in general use.
The steps of the comparison process are the following:
- Documents are converted to text
- Words are lemmatized (assigned basic forms so plurals/singulars are treated as the same)
- Parts of speech are tagged
- “Term grammar” rules specific to each language are applied, as each language has rules defining what constitutes a term structure, for example:
- English: noun, two nouns, adjective + noun, etc.
- Spanish: different rules (can’t have two nouns together without preposition/article)
Frequency comparison process: The tool identifies potential terms based on grammatical patterns, then compares their frequency in the document versus the general corpus:
- Higher frequency in document than general language = likely term
- Much lower frequency in general corpus = even stronger term candidate
- Equal or higher frequency in general language = not a term
Will AI be able to perform term extraction?
While AI can find some terms, it doesn’t complete the terminology extraction task comprehensively, making it unsuitable for this specific application despite its usefulness in other areas.
Despite the company using AI for other purposes, AI is not well-suited for terminology extraction. Because AI learns from human-produced texts and data, it can only identify terms that were explicitly marked as terms in its training data – essentially terms that already exist and have been previously identified.
Terminology extraction tools should be able to identify completely new terms that have never existed before, including company-specific terminology that no other organization uses. The speaker gives an example of working at a company that had unique terms not used elsewhere.
In a direct test using the same document presented earlier:
An AI tool found approximately 85 terms
OneClick Terms found around 600 terms
Q&A from the audience
Q. How do you handle data privacy?
How are our highly confidential documents protected when
using this online tool? Are documents stored after processing? Do you have an
offline desktop version available?
A.The tool is exclusively online because it requires access
to 660 billion words of reference data that cannot be installed on individual
computers.
We have implemented the following data security measures:
- Each user has their own private account
- Data is uploaded only to the individual user’s account
- No one else has access to the uploaded data
- The company doesn’t use the data for any purpose
- They don’t even want to access the data because they don’t know what it contains
- The company holds an ISO certificate for Electronic Security.
Q. Can you explain your pricing model?
A.We have a subscription model. If you are a freelancer, the
cost is 140 euros per year for 12 months. A monthly subscription is also
possible. If you are a language service provider, we offer a corporate
subscription. Its cost is determined on a case-by-case basis by the volume of
data you expect to upload.
Q. Do you offer a trial version of OneClick Terms?
A. Yes, you can sign-up for a 30-day trial.
Q. How can I get support with OneClick Terms?
A. You can click the “Request support” button found at the
bottom of all pages. We offer live support from 9:00 am to 5:00 pm CET. We are
committed to responding to you within hours or the following workday. The
support team consists of trained linguists, computational linguists, and experts
in natural language processing. We are able to understand any linguistic
question in any language.
Q. What is the learning curve for using OneClick Terms? And
can a new user acquire the knowledge to use your tool in an optimal way?
A. The “START HERE” button is quite intuitive. The other
SketchEngine functionalities are a bit more complex. We have online tutorials
through our YouTube channel. The videos are short and concise. We also organize
face-to-face courses.
Q. Can I create my own corpus of “reference language” before
starting a project, for example, choose texts that are exclusively written in
one specific Spanish language variant?
A. OneClick Terms supports all varieties of Spanish without
needing specific settings – it works universally across different Spanish variants.
For the full SketchEngine platform, users have two main options:
Pre-built Spanish corpus:
- Contains 28 billion words of Spanish text
- Already divided into regional subcorpora including Chilean, Colombian, Dominican, Ecuadorian, and others
- Allows searches within specific regional variants
Custom corpus creation: Users can build their own Spanish corpus by:
- Naming their corpus
- Selecting Spanish as the language
- Gathering data from the internet or uploading their own documents
- Creating a corpus focused on a specific Spanish variety if desired.
Q. When building your general language corpus, do you have
access to content that is protected by passwords, for example media or
specialized publications?
A. No, our corpora are built on public information only.
Q. What kind of functionalities are you currently working on
developing?
A. A large share of our work consists in building new corpora with the latest data. We are also looking at expanding the number of supported languages.
For more details about this post, please visit OneClickTerms.
Disclosure: Claude has been a contributor to this blog post.