
By Nora Díaz
For a translator looking to save time and improve productivity, regular expressions, also known as regex, provide a valuable tool that can be used whenever a pattern can be identified. However, at
first sight, regular expressions can be intimidating and seem difficult to learn, keeping us from what could be a fantastic asset. While learning everything there is to know about regular expressions may seem like a daunting task, there is in fact a lot that can be learned in a short amount of time that can have a positive and immediate impact on a translator’s productivity. Read on to start picking the low-hanging fruit right away.
What are Regular Expressions?
Regular expressions are representations of patterns that can help us match strings of text. These matchescan then be used, for example, in Find and Replace operations to help save us time.
As an example, the regular expression \s\d{2}\smm signifies a space, followed by two digits, followed by a space, followed by the letters mm.
A Sample Use Case
So, what can regular expressions do for you? Imagine that you have to deal with a document where there are extra blank spaces in front of different punctuation marks. To delete the extra blank spaces, you have several options:
1. You could go through the text and manually delete the extra spaces one by one.
2. You could run several individual find and replace operations to find “space followed by a comma”, “space followed by a period,” “space followed by a question mark,” and “space followed by a closing parenthesis” patterns and remove the spaces.
3. You could use a regular expression in the Find and Replace operation to find all instances of “space followed by a punctuation mark that is either a period, a comma, a closing parenthesis or a question mark” to find all instances at once and remove all the extra spaces in a single sweep.
To achieve number 3, you could use a regex such as this one,
\s[.,)?]
which signifies the following:

Where Can Regular Expressions Be Used?
There are many programs that support regular expressions in a variety of operations.
For example, Aegisub supports regex in Find and Replace operations. To enable regular expressions, you must check the appropriate box.
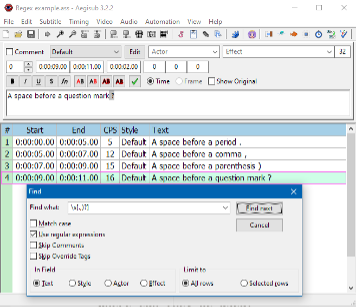
Regex in Aegisub
CAT Tools such as SDL Trados Studio, MemoQ and WordFast also support regular expressions, not only in Find and Replace operations, but also for actions such as filtering, segmentation and
verification. In fact, in SDL Trados Studio the display filter has regular expressions enabled by default.
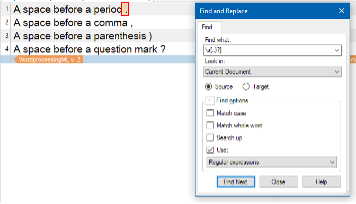
Regex in Trados
An important factor to keep in mind when it comes to regular expressions is that there are several “flavors,” and one must use the appropriate one for the program at hand. For example, both Trados and MemoQ use .NET regular expressions, while Aegisub uses Perl.
This means that there are variations in syntax that have to be taken into account when building regular expressions.
How Are Regular Expressions Built?
Regular expressions are made up of elements that have special meanings.
The following is a summary of elements used in .NET regex that are relevant for translators.
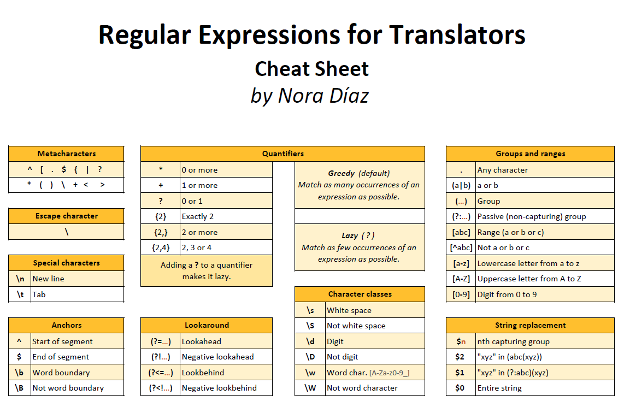
A detailed explanation of every element in this cheat sheet is beyond the scope of this article, but let’s have a look at just two of the element groups shown here: metacharacters and character classes, with a brief mention of quantifiers.
Metacharacters
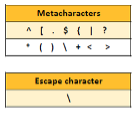
These characters have a special meaning in regular expressions and therefore cannot be used literally. To use a metacharacter with its literal meaning, it must be escaped with a backslash. This means that when using regular expressions, one can’t just use a dollar sign or a question mark and expect it to be interpreted literally. Instead, these characters must be preceded by a backslash.
For example, to create a regular expression that means “a dollar sign followed by any digit,” we need to escape the dollar sign as follows:
\$\d
The above regex would match the following:
$1
$2
$3
and every other dollar-sign-plus-digit combination, in fact.
You may be wondering why in one of the first sample regular expressions presented in this article, \s[.,)?], the period, closing parenthesis and question mark are not escaped, since they are all metacharacters and according to the explanation above would, in fact, need to be escaped. The reason is that in this regex they are being presented as part of a range, inside square brackets, and this is the only case when they don’t need to be escaped.
Character Classes and Quantifiers
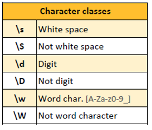

The character classes listed here, in combination with quantifiers (how many times the character class should be found in a match), are extremely useful to start building regular expressions.
For example, a regex that matches a word character (any letter from a to z), any number from 0 to 9, or an underscore, repeated one or more times (represented by the plus sign) can match full words and alphanumeric strings.
\w+
Testing Your Regular Expressions
Building regular expressions, especially when you’re first starting out, can feel like guesswork: will this match what I need it to match? Luckily, there are several free online tools to test your regexes and even help you build them as you go. You enter your regex and provide a sample text or strings to test it on. The tester will color the sections of your sample text matched by the regex. To find a tester, just go to your browser and search for “regex tester.” Play around with the various options until you find one that you like.
Here’s an example of one such tester, called Regex Storm .NET, using the above regex and a sample text:
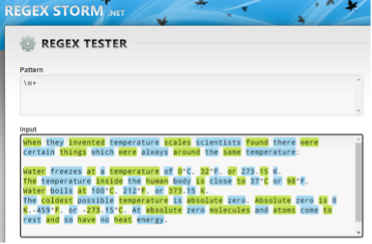
Every colored string is one match for the regex provided, so “When,” “they,” and “invented” are each individual matches for the regex \w+.
A regex to match the figures with decimals in this text could look like this:
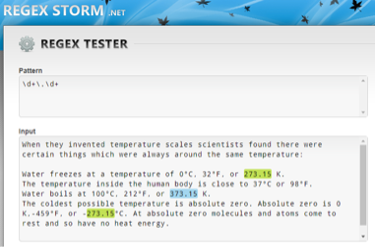
This regex is matched by any digit, one or more times, followed by a period, followed by any digit, one or more times, which is why 273.15 and 373.15 are found as matches, but 37 and 100 are not.
And, finally, a regex to match all the temperatures in this text could look like this:
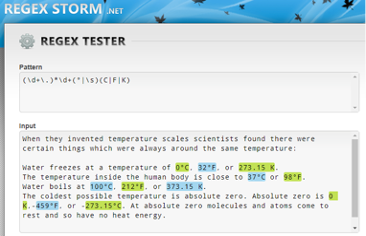
This regex may seem more complex, but it actually only introduces two additional concepts: groups and alternation. To interpret the regex above, we break it down as follows:
(\d+\.)*
Any digit, one or more times, followed by a period. This is all placed in a group, indicated by the parentheses. This entire group can occur zero or more times, as indicated by the quantifier *.
\d+
Any digit, one or more times.
(°|\s)
The degree symbol or a space. The vertical bar indicates alternation, one element or the other.
(C|F|K)
The letter C or the letter F or the letter K. Again, the vertical bar indicates alternation.
While regular expressions may seem difficult at first, once we start using them, it’s easy to think of many use cases that can help us work faster and more efficiently, and the time we invest in learning how to use them is certainly well spent.