
by Sebastián Arias
Translated from Spanish by Lucía Hernández
AI’s popularity has grown in recent years, and one notable example of its potential is AlphaGo, software developed by DeepMind Technologies. This software uses a neural network to learn to play the game Go by analyzing moves made by professional players. If you’re unfamiliar with Go, it’s a strategic boardgame developed in China over 2,500 years ago with black and white stones on a grid.
Once AlphaGo understood the game mechanics, its abilities improved so much that it began to play moves that followed the logic of the game but had never been considered by a human, ultimately leading it to beat the South Korean world champion, Lee Sedol, in 2016.
Other Applications of AI
While AlphaGo offers an early example of AI’s potential, the ability of neural networks to use large amounts of data to learn independently is now being used to solve more and more complex problems in diverse arenas. This has enabled innovative changes and previously unimagined applications, leading to meaningful advances in task automation and real-time decision making.
Over the past two years, many use cases for AI have been developed. AI technology is advancing so quickly that it’s likely the information in this article will be outdated by the time you finish reading it.
We’ve all heard of ChatGPT, which has captured headlines the world over for months, but what’s it all about? Rather than defining it, let’s let GPT-3 describe itself:
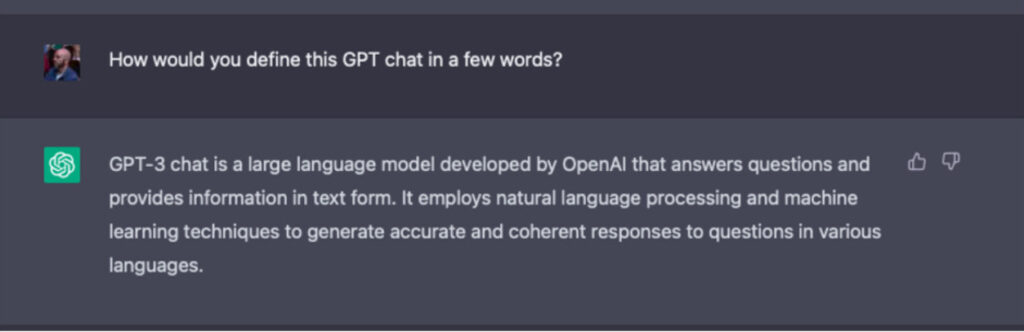
In addition to its ability to converse, AI has been used to generate hyperrealist imagery, design graphics from scratch, edit videos, write research and journalism, code and more. The list is constantly growing.
Despite its varied use cases, this article will set aside machine translation and post-editing, which have been discussed at length, and focus on recent innovations for dubbing.
The Dubbing Process
Before diving in, let’s review the main features of the dubbing process, as compared with subtitling. Subtitling only requires the creation of a text file that is superimposed onto original content. While production time can vary depending on the content’s runtime and complexity, subtitling can be carried out by a single translator.
Dubbing, on the other hand, is more involved, as it requires the recording of voice actors working closely with a dubbing director, a translator and a sound engineer. In practice, any audiovisual content can be dubbed in voice over (aka UN style).
In this type of dubbing, commonly used in documentaries and reality shows, the original language track is played at a low volume and overlayed by a target language track.
Synchronized dubbing, on the other hand, is a bit different. Here the aim is to ensure that the translation is synchronized to on-screen characters’ lip movements. Dubbing doesn’t require reading, thus increasing its accessibility, especially on mobile devices. Due to its complex nature, dubbing usually takes longer and is more costly than subtitling. Well, that is until recently.
Things are Changing
Papercup, a London-based company, uses text-to-speech technology with a focus on voice modelling to make synthetic voices sound more natural and expressive. This means, when dubbing UN style, rather than using a group of actors to record dialogue, the software “reads” translated lines using surprisingly natural-sounding synthetic voices, to create a target language audio track that is superimposed on original voices.
This naturalness is achieved through deep learning. Just as AlphaGo “learned” to play Go from professional players, Papercup used thousands of hours of people speaking to learn prosody, intonation, tone, accents, etc. Interestingly, the data used was more than 47,000 hours of podcasts made available for research and development on Spotify. Source: https://engineering.papercup.com/posts/interspeech2022-tts-overview/
This innovative production model has enabled unprecedented turnaround times. Conventional dubbing of 100 minutes of video, including translation, adaptation, recording, and mixing, takes three to four weeks. Papercup can do it in one week.
But that’s not the only difference. It costs significantly less. In the previous example, conventional dubbing would cost approximately $20,000, while Papercup can do it for 80% less. Source: https://www.papercup.com/blog/why-now-is-the-time-to-adopt-ai-dubbing
While their technology is emerging, its results can already be seen on two YouTube channels: Bloomberg en español, a news channel, and chef Jamie Oliver’s Spanish-language channel.
Does it really sound natural? While there’s room for improvement, it seems that it’s only a matter of time.
Another company using deep learning and AI algorithms to disrupt the dubbing process is DeepDub.ai. Their focus is on making voices have the same timbre as the original, even in different languages. So, for example, you can make Pedro Pascal speak Croatian without having him learn the language and record the lines. deepdub | Global entertainment experience, reimagined.
Other Related Apps
In a recent post, GPT itself declared, “AI will not steal your job. A person who is comfortable using AI will!” So, the least we could do is familiarize ourselves with this new technology. To this end, we’re sharing a brief list of game-changing apps that can streamline the dubbing production workflow in ways previously unimagined.
TrueSync
Dubbing is a post-production sound service, meaning we “work” on the sound track and adjust it as required by the image. For example, so on-screen characters actually look like they’re saying what you hear, we change the order of utterances or modify grammar in the translation to achieve synchronicity with onscreen mouth movements. Now, this is changing.
TrueSync goes about this another way. Their technology modifies video so that lips sync with a sound track in any language. The software digitally changes mouth movements so that Pedro Pascal’s lips synch perfectly to Greek dubbing, for example. The result is a convincing image of an actor speaking the language of your choosing. https://www.youtube.com/watch?v=iQ1OPpj8gPA
Lalal.ai
When content reaches a dubbing studio, its audio is usually on two separate tracks: 1. dialogue and 2. music and effects (M&E). M&E contains music, ambient sounds, and foley (sounds made by footsteps, objects, clothing, etc.). Dubbing replaces the original dialogue track with target language voice actors. This track is then mixed with the M&E track so that when an actor says, “Prepare to die,” a gunshot can be heard right on cue.
Usually, for recent big-budget movies, a track is created during audio postproduction for dubbing into several languages. While being provided this separate track is ideal, for low-budget films or ones where this wasn’t considered when the film was first produced, this is often not the case. This complicates matters.
But this is also changing. If we don’t have access to two separate tracks, Lalal.ai can separate and erase dialogue from sound tracks like non-musical karaoke. Then, we can mix target language dialogue on this track to achieve professional dubbing.
Vocalremover.org
Vocalremover.org is similar to Lalal.ai, but for music and songs. This free online application allows you to remove vocals from a song to create a karaoke track.
You upload a song from your computer. Then AI separates the vocals from the instrumentals. You get two tracks: a karaoke version of your song (no vocals) and an acapella version (isolated vocals). This process usually takes about 10 seconds.
Respeecher
While Papercup uses text-to-speech technology to disrupt the conventional dubbing process, Respeecher converts speech to speech by transforming spoken content with different characteristics. It applies a filter to the voice, not unlike Instagram filters that rejuvenate and beautify images. This technology takes a voice and makes it sound younger, older, like another gender, or even another person. This technology could be disruptive to documentary dubbing production as one actor could voice all lines, and this filter would round out the rest of the cast.
Abigail Savage works ADR magic with Respeecher’s Voice Marketplace
This technology has been used on The Mandalorian to create a younger version of Luke Skywalker. Before the voice was “rejuvenated,” it had to be “cloned.”. On their website, they explain that their system can “learn” a voice with one or two hours of high-quality recordings. But, clearly progress has been made, because Anna Bulakh, Head of Ethics and Partnerships at Respeecher, stated at Media & Entertainment Services Alliance (MESA)’s ITS: Localisation! event that a 30-minute or even two-minute sample was sufficient. https://www.respeecher.com/case-studies/respeecher-synthesized-younger-luke-skywalkers-voice-disneys-mandalorian
Synthesia
This app creates videos of a hyperrealist AI avatar with lips that synchronize to text in more than 120 languages, as if they were really reading your script. With a script of your own making, you can make a video with an AI speaker saying whatever you need to communicate. This technology is ideal for how-to videos and e-learning. It’s best understood by seeing it, so check it out at: How are Synthesia AI Avatars created?
Another company, SignAll, uses similar technology to generate sign language interpretation.
Reverso
While this app doesn’t work with voices, it could be invaluable to a dubbing translator. Reverso is a multilingual thesaurus that contains all the usual resources found in a dictionary, and using AI and its Rephraser tool, also offers analogies, reformulates phrases, offers alternatives and improves the flow of poorly written sentences.
Is the future synthetic?
Deep Blue’s victory over Kasparov in 1997 made us question the limits of professional chess players. Nevertheless, some 20 years later, computers are used to train players to get better and be more creative, and chess is more popular than ever.
Perhaps dubbing will go through similar changes. In some genres, the use of synthetic voices is no longer science fiction, but reality. The fact remains, though, that for film, while some aspects can be improved, voice acting still cannot be replaced by a machine. Nonetheless, with the speed at which technology is advancing, this could change. For example, in the time it took to write this article, Vox News, Sky News, and even the BBC, The Guardian and The Washington Post started to localize their content using Papercup.
AI is a powerful tool that can change the world. When integrated into content production, it can streamline and improve many limitations inherent to the multilingual dubbing process. By automating tedious tasks so we can focus our time and resources on our strengths as humans―creativity, problem solving and teamwork―, AI can help dubbing better deliver on its goal: to make information more accessible to greater and more diverse audiences.
Sebastián Arias is a freelance dubbing director. He teaches adaptation for dubbing at TalleresTAV.com, which he founded, and Sofía E. Broquen de Spangenberg Higher Education School. He holds a degree in Audio-vision and from 2006 to 2018, he worked as a dubbing director for Civisa Media where he recorded over 1,700 hours of documentaries, films, and series. He also works as project advisor and QC specialist of LatAm Spanish dubbing for different studios. Instagram: @sebastian_arias_doblaje. Contact: doblaje.arias@gmail.com